
Part 3: The North Star: Weekly Active Workflows (WAW)
Growth in the Age of Agents: After AARRR

In every era of growth, there’s one metric that actually matters. At Weights & Biases, it was Weekly Returning Engaged Users. Everything we did flowed through that one number.
In the agent era, that metric changes. If your product is being used by agents, at scale, autonomously, then you don’t have users in the traditional sense. You have workflows.
And that leads to a different north star entirely.
In the agent era, WAW (Weekly Active Workflows) is that metric. Here’s why the alignment matters: when your north star is the workflow and your pricing unit is the workflow, every growth experiment moves revenue, and every revenue decision improves the growth motion. You’re not optimizing two separate machines. You’re optimizing one.
A “workflow” is an agent-driven sequence of calls that accomplishes a defined task, not just any API call, but a connected sequence starting with a goal and ending with a verifiable outcome. WAW counts distinct workflows invoking your product at least once in a given week, above a minimum success threshold (>80% completion rate).
Why WAW captures what other metrics miss:
Agents don’t have “active days.” A workflow might run 50 times in 10 minutes Tuesday, then not again until Thursday. DAU/MAU cannot capture this.
Raw API call counts can be dominated by one broken agent hammering your API. WAW requires successful, goal-directed sequences.
“Weekly” filters out stale configs. “Active” filters out broken workflows generating errors. Together: you’re embedded in something being actively built.
WAW vs. Other Options
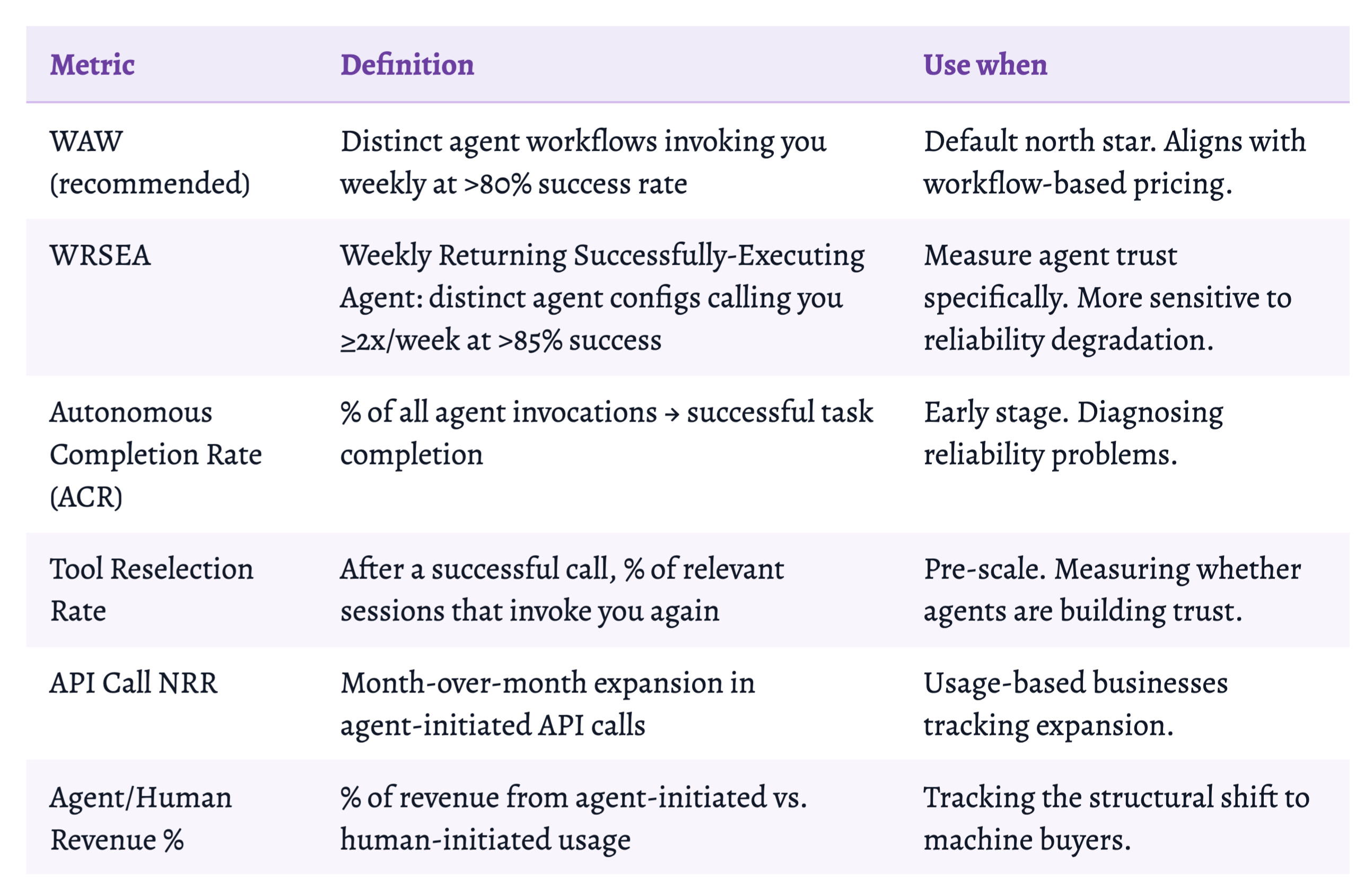
Track both WAW and WRSEA. WAW for external reporting and pricing alignment. WRSEA as your internal reliability signal, it catches quality degradation before WAW does. When WRSEA starts declining while WAW holds steady, you have a reliability problem that’s about to become a retention problem.
From the W&B playbook
When the WREU dipped, we knew within 48 hours which cohort, which channel, which part of the funnel. Get one person on your team obsessed with growing WAW, and give them the influence to act on it. A single metric gives you a chance to be genuinely creative, because every creative decision has to answer one question.
Token-to-Value
Time-to-value was the central PLG metric: how quickly does a user reach their aha moment? Dropbox optimized to minutes. Slack to a first message.
Token-to-value is its agent-era counterpart: how many tokens does it take an agent to confidently pick your product, and how many more to implement it correctly?
Agents make tool selections under implicit token budget pressure. Every ambiguity is a cost. Every missing example forces a guess. The agent picks the thing it can implement in the fewest tokens.
Resend vs. SendGrid: Same Outcome, Completely Different Token Cost
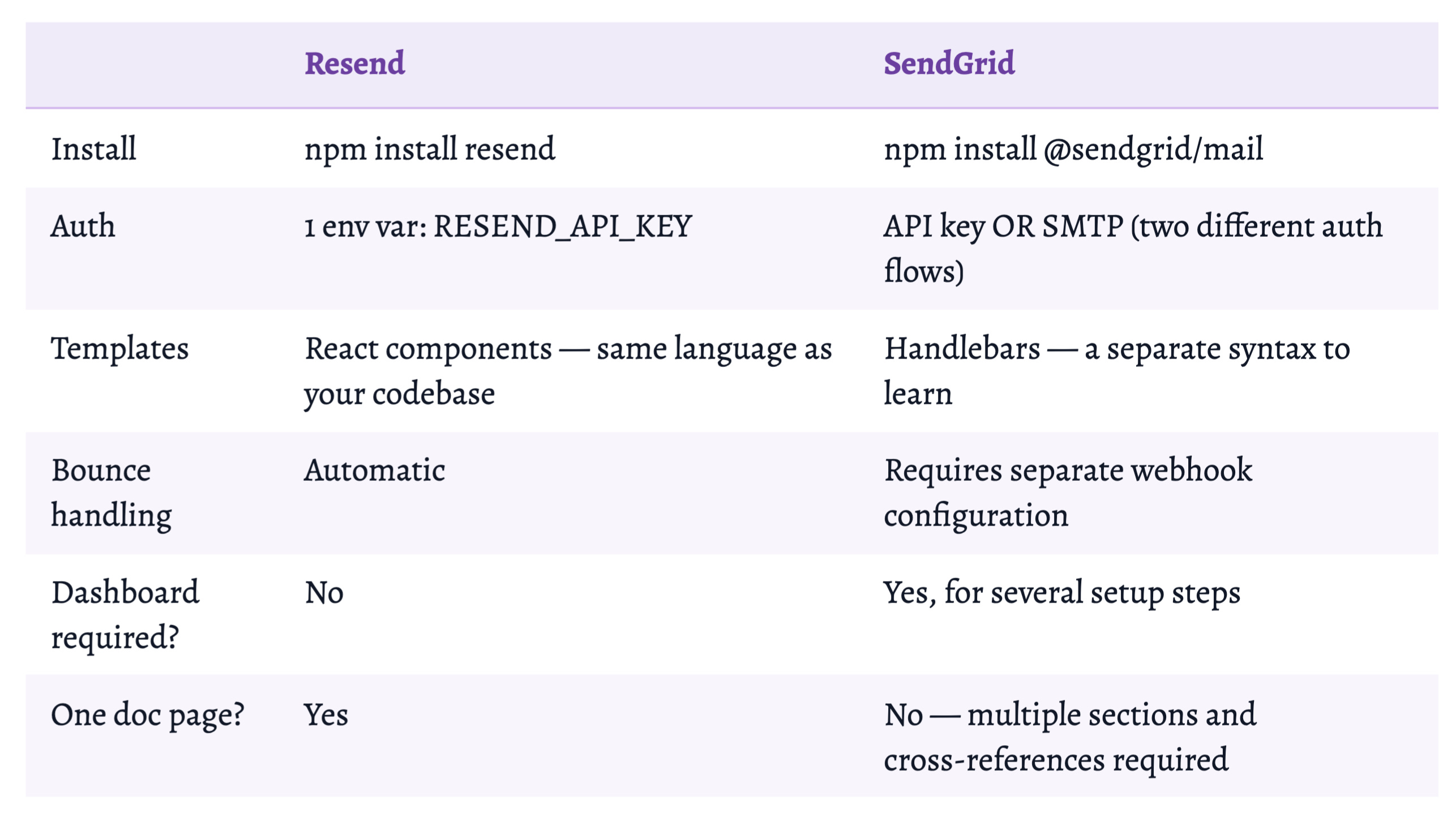
SendGrid is not bad infrastructure. For enterprise email with dedicated IPs, its deliverability track record is genuinely valuable. But for an agent writing email code in a single pass, Resend’s token-to-value is dramatically lower. The agent picks what it can implement without iteration.
The four drivers:
Description clarity: MCP tool descriptions should state when to invoke you vs. alternatives. Agents fail at tool selection when 30+ descriptions overlap. Under 8 tools per server. “Sends a transactional email and returns delivery status” not “Calls POST /v1/emails.”
Error message specificity: every 4xx is a branching decision. e.g. “Unauthorized” = 0/3. “API key missing, set RESEND_API_KEY, should start with re_” = 3/3.
API surface predictability: schema changes cost trust. Parameter names that don’t mean what they imply cost tokens.
Autonomous completability: any required human action is a hard blocker. Agents cannot click. Agents cannot check email. Agents cannot enter a credit card.
Cloudflare’s architectural solution: 2,500 endpoints would consume 1M+ tokens as individual MCP tools. Code Mode: two tools, search() and execute(), agent writes TypeScript against a typed API representation. ~1,000 tokens total. A 1,000x improvement by treating it as an architecture problem, not a documentation problem.
It’s 2026. Build. For. Agents.
The current moment is 2012 in PLG. Dropbox and Slack moved early. They built distribution advantages that compounded for a decade. Most companies were still optimizing human onboarding flows while the Dropbox referral program was already running. The winners from that era look obvious now. They didn’t at the time.
The same window is open now. Most developer tools have no llms.txt, no MCP server, no Agent Skills, no free tier accessible to autonomous agents, and no metrics that distinguish agent-driven from human-driven usage. They’re optimizing human onboarding flows while the default stacks of 2027 are being determined.
The flywheel is already spinning for some companies. Supabase didn’t win a marketing contest. It won a training data and distribution architecture competition that started years before anyone called it that. Resend didn’t out-sell SendGrid. It out-documented and out-simplified it, until a machine could implement it correctly in a single pass, and confidently recommend it to the next machine that asked.
Every successful agent execution is a vote in the next round of training. Every public repo is a permanent signal. Every community config template is an H2A conversion waiting to be cloned. The referral loop closes automatically. The flywheel spins on its own.
The rules of this competition are now clear. The window to enter it is still open.
“It’s 2026. Build. For. Agents.” – Andrej Karpathy
Thank you to Lukas Biewald, James Cham, Amy Tam and Phil Gurbacki for early feedback on this draft.
Part 4 – The Agent Flywheel Checklist is the implementation guide companion to this piece, with specific examples from the companies doing it well.

_________________________
Lavanya Shukla is the Managing Partner of Improbability.vc, an early-stage fund backed by Sequoia, Coatue, Village Global, Bloomberg Beta, Lukas Biewald, Adrien Treuille, and AI leaders at OpenAI, DeepMind, Turing et all.
She spent seven years running Growth and AI at Weights & Biases, scaling it from 100 users to millions, every AI engineer at every major lab, through product-led growth.
Improbability Engine’s thesis: invest in the 1–2 AI companies that matter every year. If you’re building one of them, reach out: lavanya@improbability.vc